第二十八回 セマンティック・セグメンテーション用のネットワーク構造
第二十七回 では、画像分類に関するネットワークの構成例について説明しました。 セマンティック・セグメンテーションの場合、いったんサイズを小さくした画像を、再び拡大する必要があり、 第二十五回 で説明した逆畳み込みが必要となります。
以下は、セマンティック・セグメンテーションで使用するネットワークの一例です。 基本的な考え方がわかりやすいように、関連する論文でよく使われるものとは異なる構造を選んでいることにご注意ください。
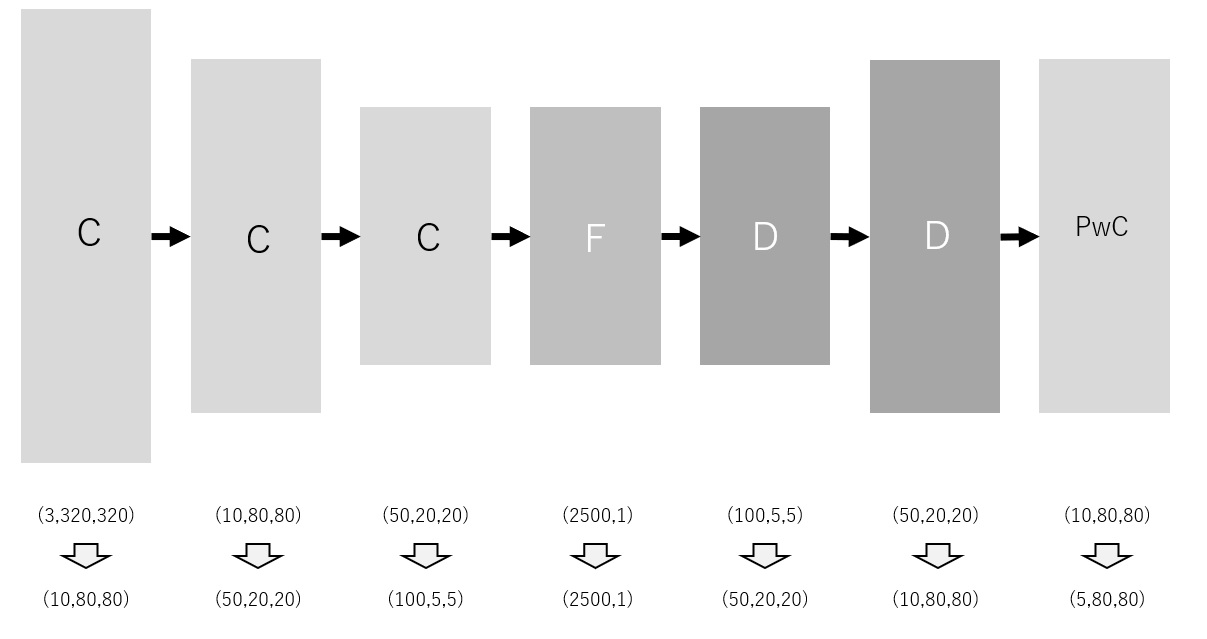
まずは、画像分類の場合と同様、複数の畳み込み層により、画像サイズを小さくしていきます。 フィルタサイズは 4×4 、ストライドも 4×4 を想定しています。 したがって、画像サイズは縦横とも4倍ずつ小さくなっていきます。 データサイズが小さくなりすぎると、ディープラーニングにより期待する結果が得られなくなる恐れがあります。 この問題を回避するため、チャンネル数を増やしながら畳み込みを行っています。 すべての畳み込み処理が終わった時点での行列サイズは (100,5,5) です。
続いて、全結合層です。 ひとつ前の畳み込み層から出力された行列を列ベクトルに変換します。 つまり、入力サイズは (2500,1) です。 上記の例では、出力サイズも同じとしていますが、もちろん、変更することも可能です。
その後、複数の逆畳み込み層により、行列サイズを拡大していきます。 最初の逆畳み込み層では、入力サイズを最後の畳み込み層での出力と合わせます。 フィルタサイズは 4×4 、ストライドも 4×4 を想定しています。 したがって、画像サイズは縦横とも4倍ずつ大きくなっていきます。 チャンネルサイズは、逆畳み込み計算の進行に従い、5へ向けてだんだん小さくしていきます。 ここで最終的なチャンネルサイズを5としている理由は、セグメンテーションを行うクラスが5個あることを想定しているためです。
最後に1x1畳み込み層を配置しています。 行列サイズは変化しません。 活性化関数にはソフトマックス関数を選択します。 ただし、全チャンネルで同じ位置となるピクセルにつき、計算を行います。 こうすることで、各ピクセルが分類されるクラス確率が取得できます。