第二十三回 LSTM
再帰型ニューラルネットワークに対して、教師データを与えてパラメータを更新しようとする場合を考えましょう。 入力するデータの数だけネットワークの層が時系列に展開されることになり、大きなデータを対象とした場合、内部で抱えるデータ量も膨大になるうえ、パラメータ更新のための誤差が発散するかゼロに収束してしまい、求める解に至らない問題が発生する可能性が高まります。
この問題を解決するため、ひとつ前の時刻の出力をそのまま利用するだけでなく、少し工夫した層が提案されています。 ここではその一例として、LSTMについて説明します。
LSTMの構造は下図の通りとなります。
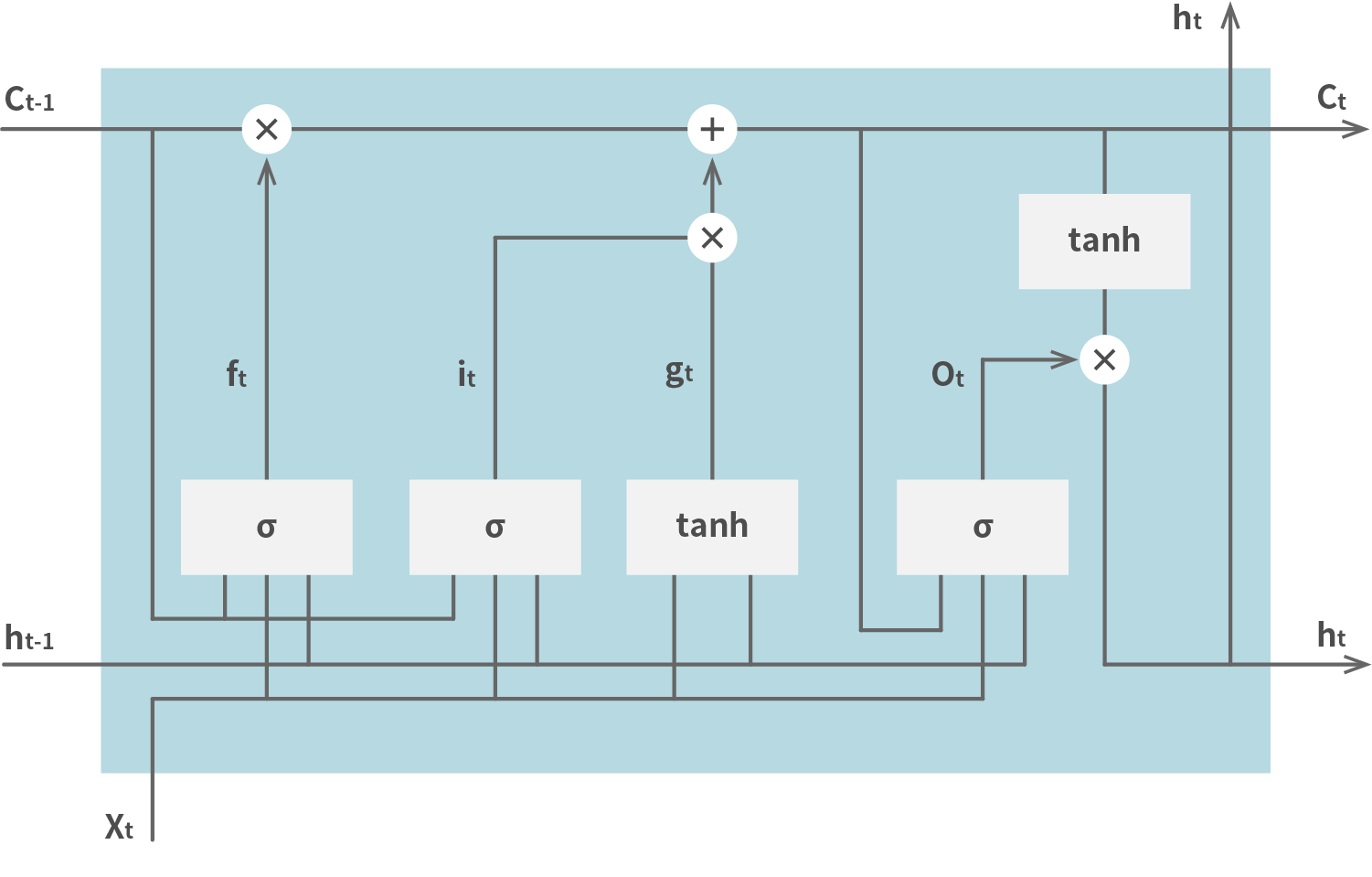
変数 c はセルと呼ばれ、ひとつ前の時刻における状態を保持します。 入力はひとつ前の時刻における出力とともに入力ゲートに与えられます。 一方(上図の it )はセルを参照し、シグモイド関数を通ったのち入力ゲートに与えます。 もう一方(上図の gt )はセルを参照せず、tanh関数を通ったのち入力ゲートに与えます。 入力ゲートからは現在の時刻におけるセルの値(上図の ct )が出力されます。 出力ゲートへの入力(上図の Ot )は、現在のセルの値と、各入力値を参照し、シグモイド関数を用いて算出します。 最終的な出力(上図の ht )は、次の時刻における入力として利用します。 ひとつ前の時刻におけるセルの値を利用しないようにするためのゲートとして忘却ゲートが用意されており、その入力値(上図の ft )により前の値を利用するかどうかが決定します。
このように様々な用途のゲートを用意することで、入力サイズが大きい場合でも、パラメータ更新に不都合を発生させないようにすることができます。