第二十一回 過学習
統計的にデータからパラメータを推定する場合、学習用データに過剰に適合したモデルが出来上がることがあります。これを過学習と呼びます。
具体例を見てみましょう。 下図は、グラフ上にプロットした計測結果を近似する曲線を作成したもので、一つ目が3次曲線、二つ目が6次曲線です。 この例では、3次曲線で十分な近似が得られており、6次曲線ではプロットがない部分で不自然な値を示しています。
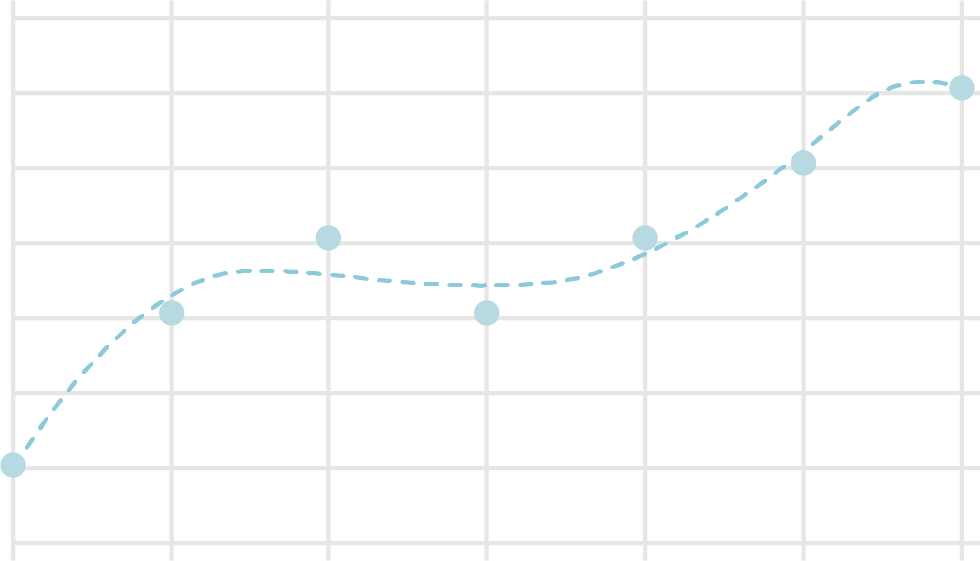
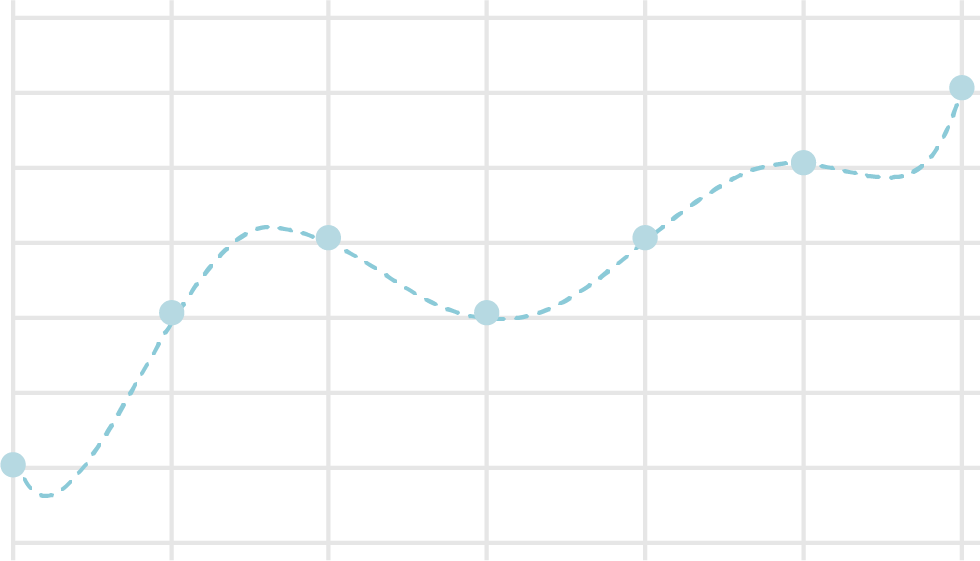
ニューラルネットワークでの過学習を防ぐ手法として、様々なものが提案されていますが、最初に正則化を説明します。
以下の式の通り、損失関数 に正則化項を加えます。
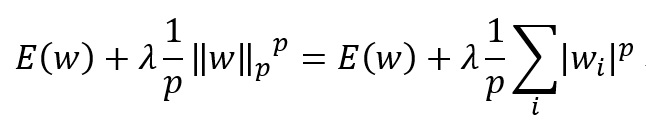
のときをそれぞれL1, L2正則化と呼びます。 なぜ正則化により過学習が防げるのかについての詳しい説明は、関連する文献に譲ります。 直感的に説明すると、パラメータのノルムが損失関数に含まれることから、その動く範囲が制限され、結果として、入力データに過剰に適合するモデルが作られにくくなります。
ニューラルネットワークではL2正則化がよく用いられます。以下にその式を記述します。
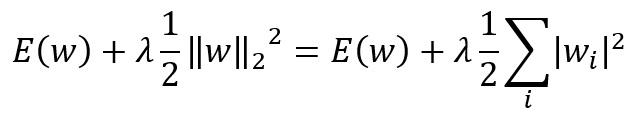
この式を微分した結果を考慮すると、ミニバッチでの更新式は以下のようになります。
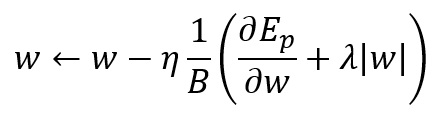
は正則化の程度を指定するパラメータで、0.01などの小さな値を指定します。
過学習を防ぐ手法として、次にドロップアウトを説明します。
学習時に、ネットワークに含まれる人工ニューロンの一部をランダムに無効化します。 1回のパラメータ更新が終わったら、無効化する要素を選びなおし、学習を行います。
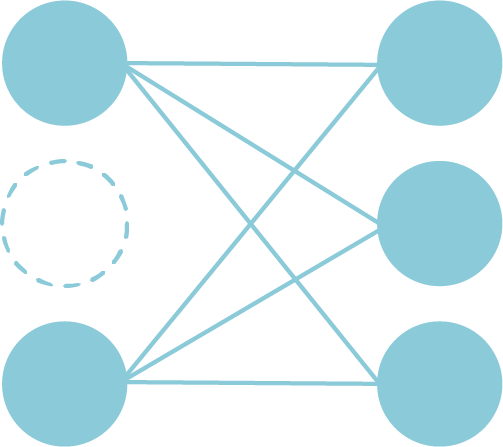
無効化する要素の比率を示すパラメータを0から1の範囲で与えます。 0.3であれば、30%の要素が無効化され、残り70%の要素を使用して計算を行うことになります。
全体の出力は、比率をpとすれば だけ減ります。 そこで、出力の値を 倍して補正します。
ドロップアウトを行うと、学習の進み具合が遅くなることが欠点で、その分学習回数を増やす必要があります。