第十五回 畳み込み
畳み込みとは、従来からある画像処理の技法のひとつで、ニューラルネットワークに与える入力値を減らすために、画像処理の場面でよく用いられます。 ニューラルネットワークに与える入力値が多ければ、それだけ調整すべきパラメータも増えていくため、誤差が十分に小さくなるまでの繰り返し回数が増えてしまいます。 そこで、機械学習に画像処理技術を組み合わせることで、より小さなニューラルネットワークを使った画像認識を行えるようになりました。
画像ファイルは、色の付いた点の集まりでできています。 一つ一つの点をピクセルと呼び、解像度により、その数が異なります。
実際の画像を十分に拡大すると、各ピクセルが肉眼でも認識できるようになります。

画像認識を行う場合、隣り合ったピクセルに描画された色の違いに意味はなく、周辺のいくつかのピクセルをまとめ、その値を何らかの計算により別の値に変換することで、目的を達成できることが多いものです。 そこで、ここで説明する畳み込みが利用されます。
コンピュータ上で色を表現する場合、赤、緑、青の三原色(RGB)のそれぞれにつき、0から255までの256階調で値を持っていることが多く、これにより、約1600万色が利用可能となっています。
ここで、縦横3ピクセルずつの大きさである画像のRGB値を数値で表したものを考えてみます。例えば、以下のようになります。
画像処理では、RGBはそれぞれ別の画像としてとらえ、チャンネルと呼びます。
これらの値を次元でとらえると、縦横の2次元に加え、RGBの3つのチャンネルが加わり、3次元のデータとして考えることができます。
それぞれのピクセル値は0から255までの値となりますが、これらに対して、何らかの演算を行い、新たな画像を得ることが、ここで対象とする処理内容です。
話を簡単にするため、グレースケール画像を考えましょう。 チャンネル数は1となりますが、これに対する演算処理に用いるフィルターを定義します。以下はその例です。
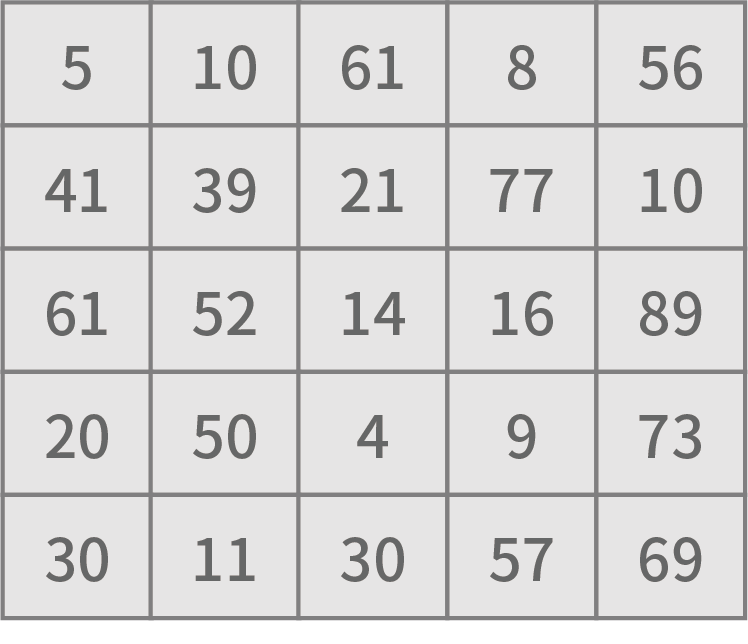

ここで例とするフィルターは、中央上が-1、中央が1、それ以外は0となっています。 元画像の左上から右下へ向けて、フィルター画像を重ね合わせ、重なったピクセル同士を掛け合わせて合計すると、新たな値が算出されます。 これを各ピクセルの値とすることで、新たな画像が出力されます。具体的には以下のようになります。
ここでは、縦横3ピクセルずつのフィルターを用意し、縦横1ピクセルずつずらしながら畳み込みを行いました。 結果として、縦横3ピクセルずつの画像が得られました。
続いて、複数チャンネルの画像についてその処理内容を見てみましょう。
すでに説明したとおり、グレースケールの画像においては、フィルター1枚による畳み込みで、1チャンネルの画像を得ることができます。 複数チャンネルの画像においては、入力チャンネル数分のフィルターによる畳み込みで、同じサイズの画像を入力チャンネル数分得ることができます。 出力された画像の同じ位置にあるピクセルの値を足し合わせることで、1枚の画像にまとめます。 フィルター群を複数用意すれば、複数チャンネルの出力画像を得ることもできます。 つまり、入力と出力のチャンネル数が一致している必要はありません。
具体的な計算例を確認してみましょう。
以下は、3チャンネルの入力画像と、2つのフィルタ群の例です。
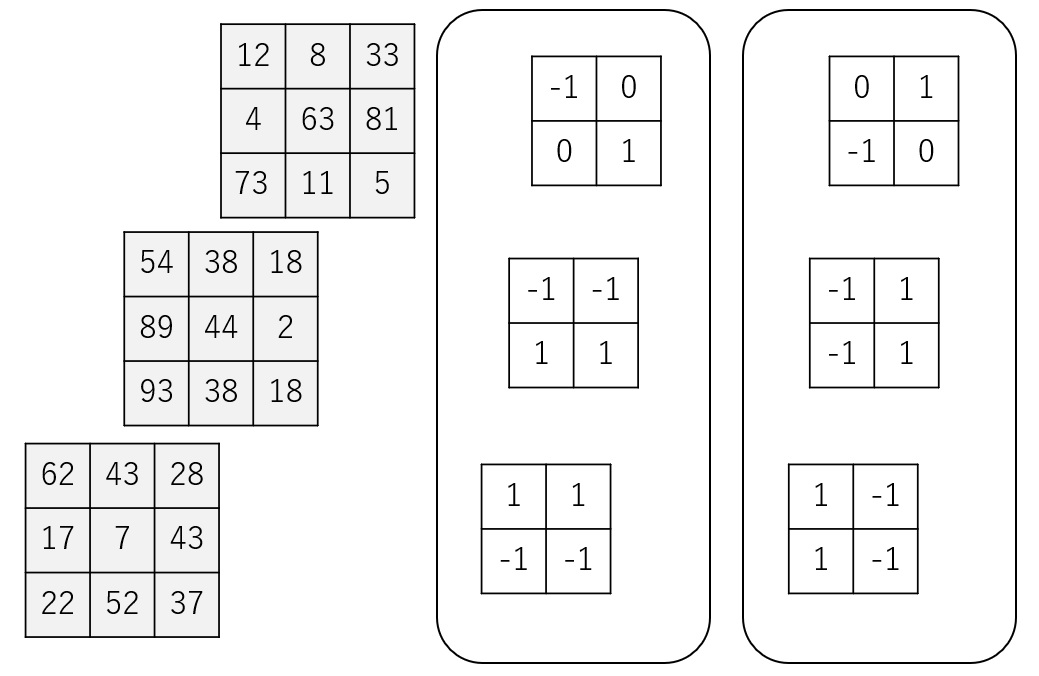
まずは、1つ目のフィルタ群を使用して畳み込みを行います。
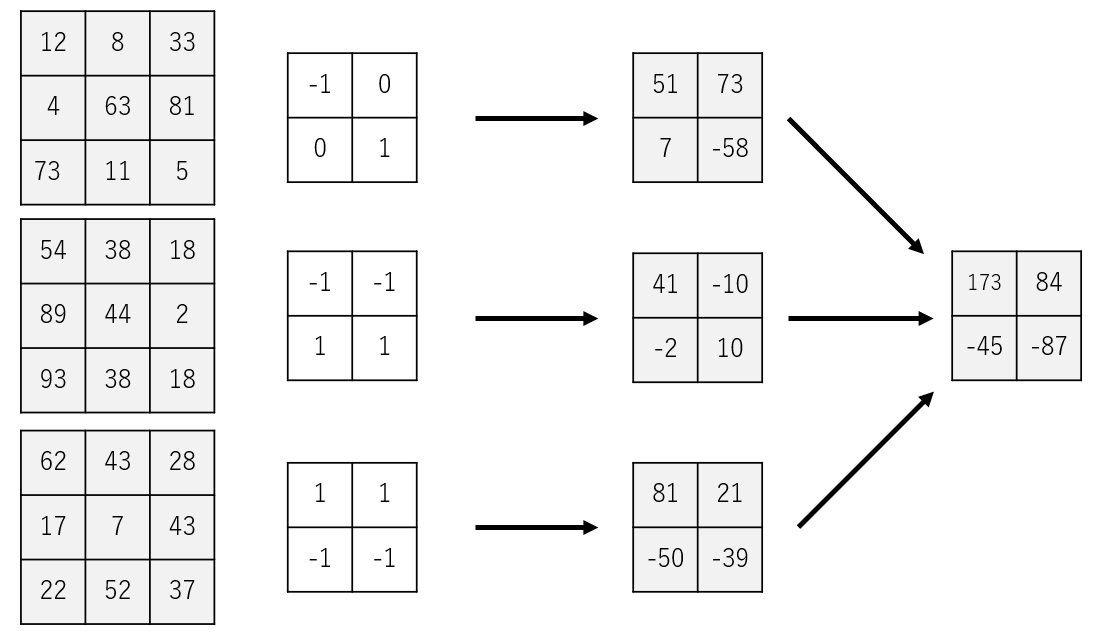
続いて、2つ目のフィルタ群を使用して畳み込みを行います。
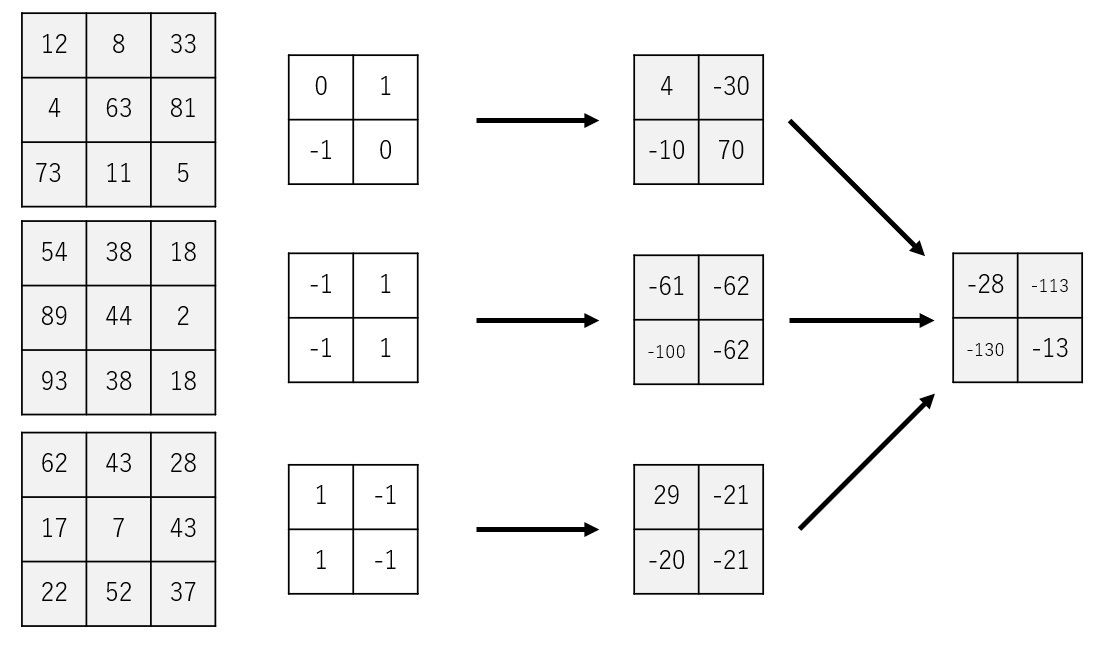
上記の例では、3x3サイズの3チャンネルの画像から、2x2サイズの2チャンネルの画像が得られました。
このようにして、畳み込み処理を行うことで、元画像の特徴を残した、より小さいピクセルサイズの新しい画像を生成することができます。 これをニューラルネットワークの入力とすることで、学習対象となるパラメータの数を減らすことができ、最終的に学習が終わるまでの時間を短縮することができます。