第十三回 人工ニューロンの概要
人工ニューロンは生物の神経細胞をモデル化したもので、以下のような構造をしています。
複数の入力を受け取り、一定の処理を行ったうえで結果を出力します。具体的には、各入力の値に決められた係数を掛けて、すべてを足し合わせます。
N個の入力がある場合について、その計算過程を見ていきます。
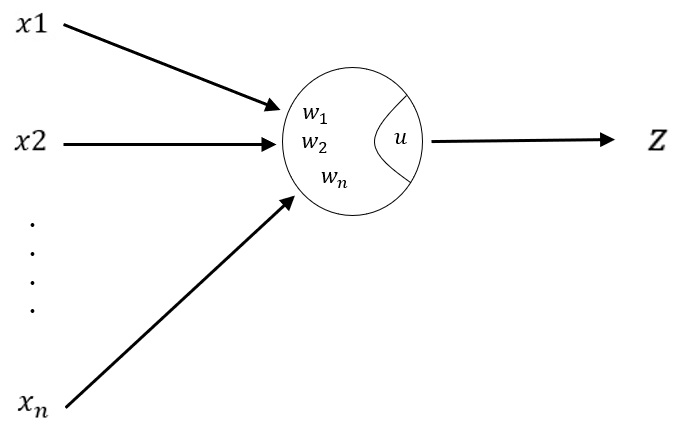
入力 について、あらかじめ決められた定数 を掛けます。 この定数 を重みと呼びます。 すべての入力について、入力と重みを掛け合わせ、合計した値を求めます。 この値にある値 を足して、出力 を得ます。 ここでの値 をバイアスと呼びます。 さらに、出力値に関数 を適用して最終出力 が決まります。 ここでの関数 を活性化関数と呼びます。
以上の過程を数式で表すと、以下のようになります。