Lesson 28 Network Architecture for Semantic Segmentation
Lesson 27 describes an example of network architecture for image classification. Regarding semantic segmentation, the network has to expand the shrinked image again. Therefore, deconvolution, which was explained at Lesson 25 is necessary.
The following is an example of network for semantic segmentation. Please keep in mind that the selected architecture is different from ones which are often used in related technical papers, so that you can understand the basic concept.
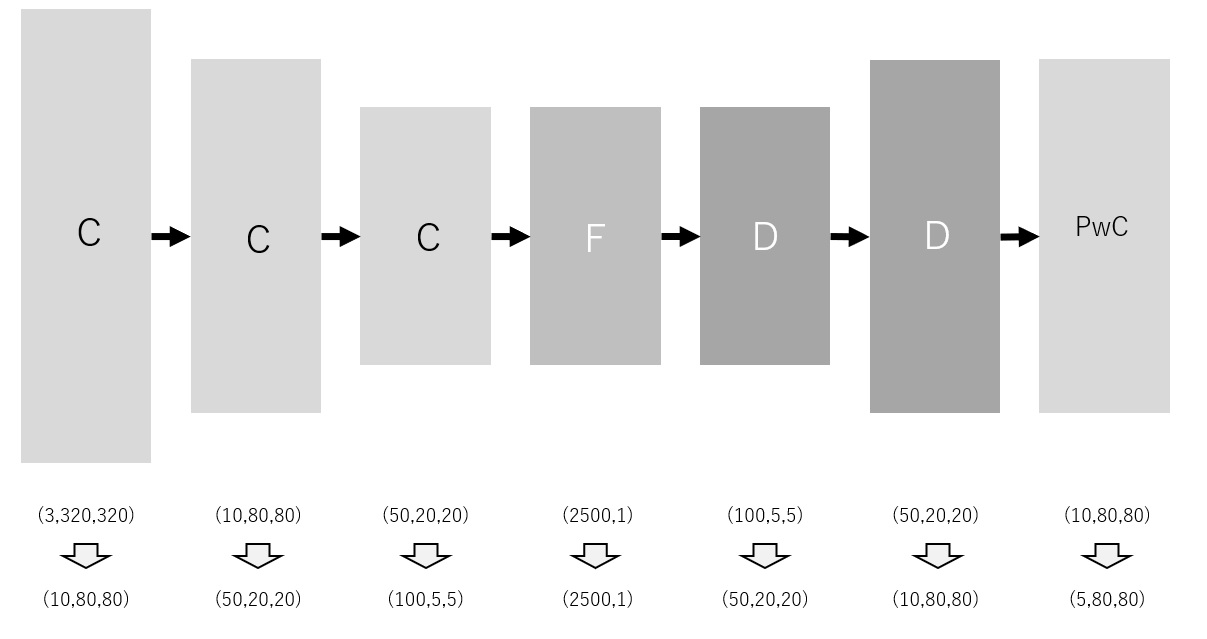
First of all, convolution layers will shrink the image size, which is same as image classification. Suppose the filter size is 4×4 , and the stride is 4×4 as well. Thus, the image size at each layer will be one fourth of the size at the previous layer. If the data size becomes too small, we may not be able to get the expected result by deep learning. To avoid this issue, convolution layers will increase the output channel counts. The matrix size after all the convolution processes is (100,5,5) .
The next step is full connection layer. The output matrix from the previous convolution layer is converted into a column vector. It means the input size is (2500,1) . In the example above, the output size is the same as the input, but it's surely possible to change it.
After that, we will expand the matrix size by multiple deconvolution layers. The first deconvolution layer converts the input into the same size as the output of the last convolution layer. Suppose the filter size is 4×4 , and the stride is 4×4 as well. Thus, the image size at each layer will be four times as large as the size at the previous layer. The channel size will decrease to the value of 5 along the calculation of deconvolution layers. The reason why we selected 5 as the final channel size is that we suppose 5 as the number of segmented classes.
The last layer is a pointwise convolution layer. The matrix size will not change. The activation function is softmax function. The calculation must be done with the pixels at the same location of all channels. And then, we can get the probability of classes on each pixel.