Lesson 29 Batch Normalization
If network hierarchy is huge, the parameter modification at a layer, which is close to the network input, will change the input distribution at following layers. And finally, the learning process may not go forward properly. Batch Normalization is to adjust the distribution of the input values per mini batch, with the mean of 0 and standard deviation of 1. It will avoid getting into the saturated region of the activation function.
Let's see how the learning process will not go forward properly, with regards to some activation functions.
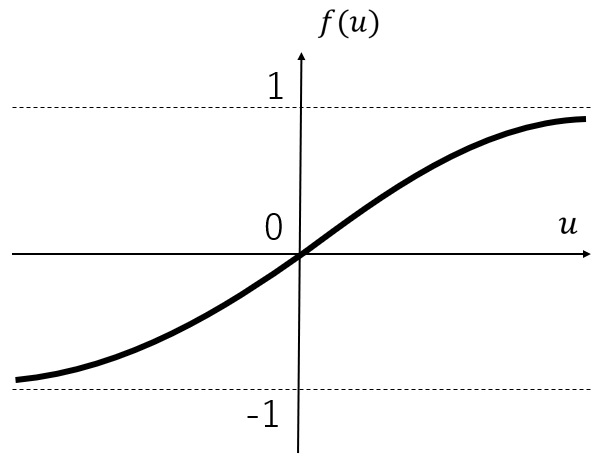
Lesson 14 shows the graph of Tanh function is as follows.
Suppose input distribution is like this.
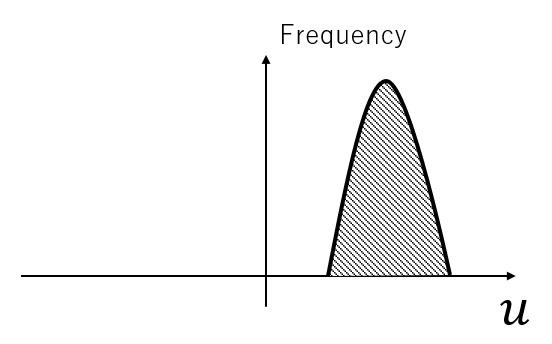
So many input values are in the area, where the inclination of Tanh graph is small. Therefore, even if the system changes the weight values dramatically, the change of output value will be comparably small. Now, we transform the input values to a new distribution whose mean is 0 and standard deviation is 1.
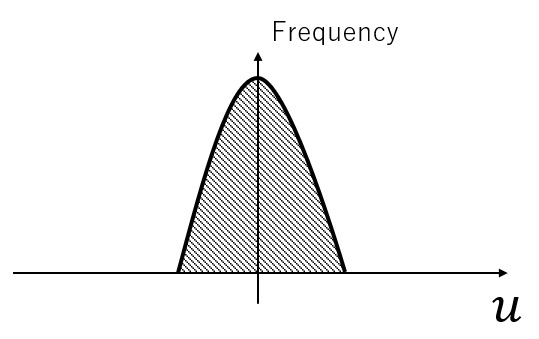
So many input values are in the area, where the inclination of Tanh graph is relatively large. As a result, the change of output value according to the input value modification will be larger.
Lesson 14 shows the graph of ReLU function is as follows.
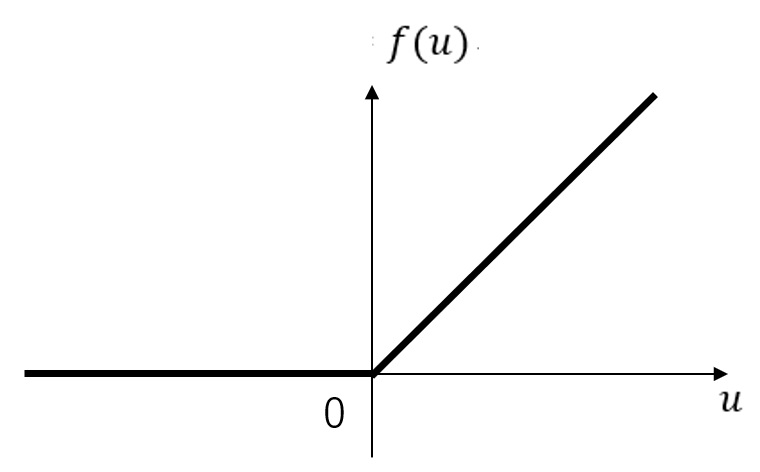
If the input distribution is at the negative area, most output values become 0, and those values are ignored during learning process. It means deep learning process may not end after a very long period.
Regarding detailed explanation on batch normalization process, please refer to professional books, as it will include very complex formulas. This process is to change input values. That's why backward propagation process also needs to consider it, and unfortunately the formula will be so difficult.