Lesson 31 Object Detection with Deep Learning
Lesson 30 describes the basic method for object detection.
Recently, we normally take advantage of deep learning technology for object detection. This article will describe the basic concept of some methods which have been proposed, and finally explain a method which utilizes deep learning for the whole object detection process.
1: Utilize Deep Learning after Bounding Box Proposal
This method takes advantage of an existing technology for bounding box proposal, and deep learning for the later steps. Some approaches are proposed, and the basic architecture is described in the image below.
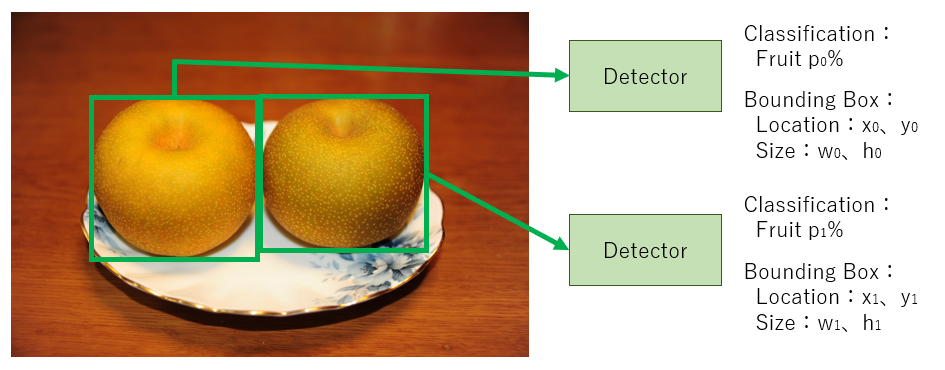
Input the extracted image from the proposed bounding box to Detector The detector calculates the classified object and its probability, and also the location and the size of the bounding box. Only one detector exists actually, while two rectangles are shown in the image above.
Regarding bounding box location and size, this algorithm calculates the offset values between proposed boxes and actual ones.
The inside architecture of the detector is shown below.
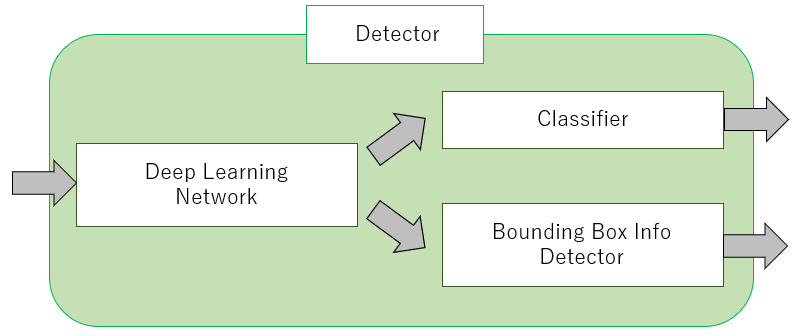
The extracted image from the bounding box is given to the detector. Then, the system gets the characteristic values with a deep learning network. The network architecture often consists of multiple convolution layers, but in some cases it may include some full connection layers.
We can get the detected class name and its probability, by giving the calculated characteristic values to the classifier. And also, we can get the offset values on bounding boxes, by giving the values to the information detector.
As we already explained, the calculation load on bounding box proposal is comparably high. Therefore, some algorithms to reduce the load are proposed. Please refer to the other books or documents for the details. We believe the description above should help you learn related algorithms, as it explains the common basic architecture.
2: Utilize Deep Learning for Whole Process
This approach is to utilize Deep Learning for the whole process, including bounding box proposal. A variety of network architectures are proposed, and the basic concept is shown in the image below.
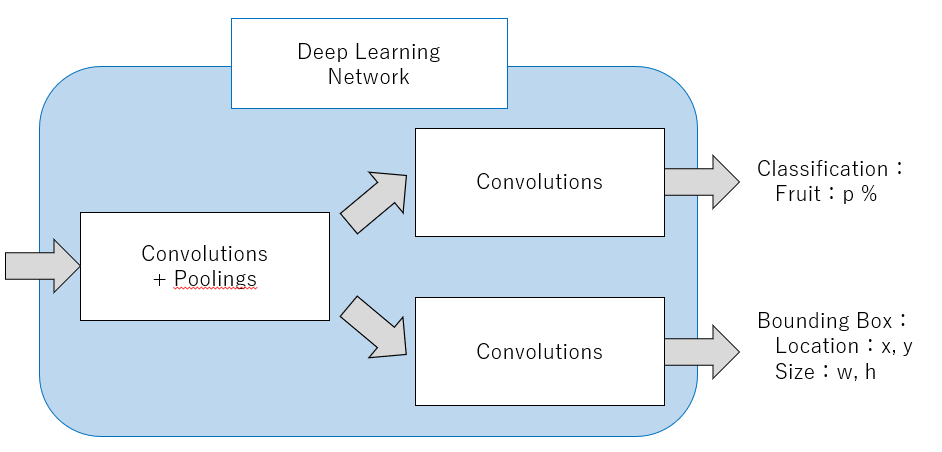
First of all, multiple convolution and pooling layers will extract the characteristic values from the input image. It is important to increase the channel size not to be short of the parameter number in each network layer, as the image size becomes smaller by moving forward.
Once the image size becomes small adequately, the process goes to the two branches. One is to classify objects, and the other is to detect bounding box information. The system recognizes the output values of the last convolution layer as classification or bounding box information respectively.
Please refer to technical books or related papers for the detailed specification of each network layer.
We have conducted deep learning trials with a lot of types of network architectures. As a result, we understand that PCs with enough performance are required to execute the calculation process. When we are going to work on object detection, we should take care of this topic before we start a project.