Lesson 23 LSTM
We are discussing what happens when a recurrent neural network updates its parameters based on a teaching data. The network will be expanded according to the size of input data count. When the input data size is big, the internal data naturally becomes big. We may find a case that the difference between the output and the teaching data for parameter update is too large or too close to zero, and finally the system gets no expected values by deep learning.
To solve this issue, a type of layer, which has some improvements on the internal architecture not to simply use the last output, are proposed. Now, we explain LSTM, which is one example.
The following diagram shows the whole architecture.
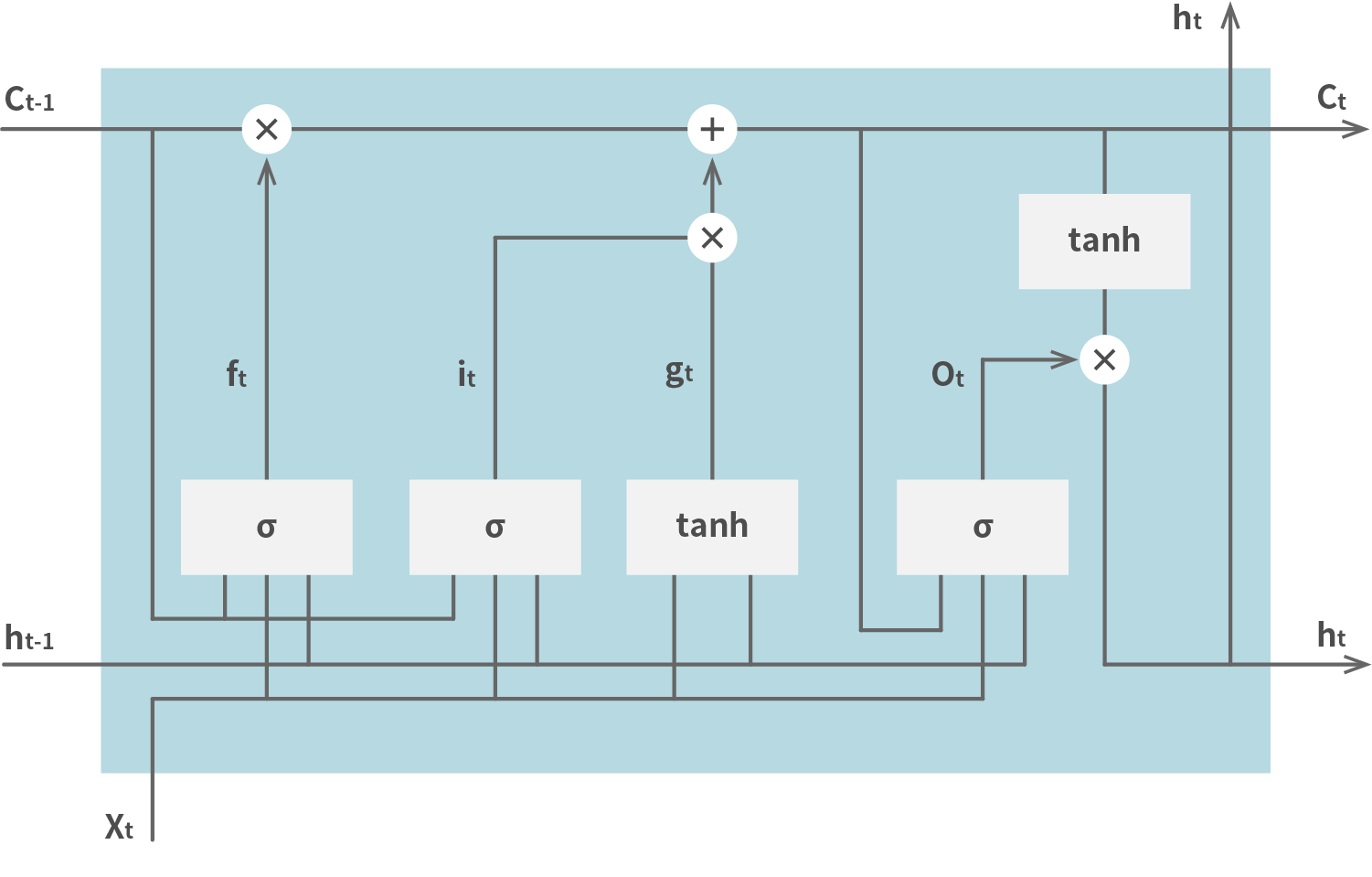
The variable c , which maintains the state at the last step, is called Cell. The system gets the input, and the output of the last step, to Input Gate. One value ( it in the diagram) refers to the cell, applies sigmoid function, and then input the result to Input Gate. The other value ( gt in the diagram) doesn't refer to the cell, applies tanh function, and then input the result to Input Gate. The gate outputs the current cell value ( ct in the diagram). The input for Output Gate ( Ot in the diagram) refers to the current cell value and some input values, and calculate the result using sigmoid function. The final output ( ht in the diagram) is used as an input of the next step. Oblivion Gate is prepared not to use the last cell value. The input value of the gate ( ft in the diagram) defines whether the system uses the last value or not.
The various types of gates, described here, are effective to solve the issues on parameter update, even if the input size is big.