Lesson 19 Learning Optimization
Suppose there is a deep valley around the current location, when the system is trying to adjust the parameters. The parameter modification becomes greater, and therefore we cannot easily go out of the valley.
Some parameter adjustment methods are proposed to solve this problem.
Momentum SGD adds a momentum item to SGD. The following is the update formula.
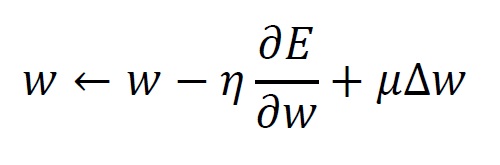
where is error between the output and teaching data, is the adjustment amount of weight at the previous iteration, and is momentum ratio.
The third item is called momentum item, as it tries to keep the previous adjustment direction. This approach is effective to solve the problem in terms of SGD, when the current location is close to a deep valley.
Adam uses the moving average of gradient, in order to take care of the last adjustment directions.
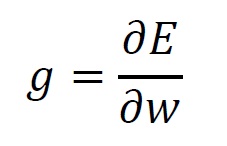
where is gradient, is weight, and is error between the output and teaching data.
And,
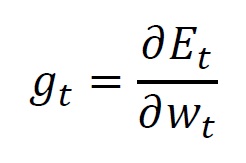
representing the current iteration step as .
Now, we are calculating average values from first order moment of gradient and second order moment of gradient. The formulas are,
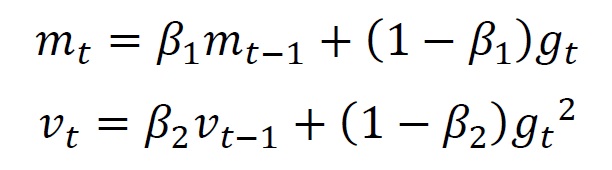
where is first order moment of gradient (Average), and is second order moment of gradient (Variance).
And then, we will conduct bias adjustment for each value. Please see related books for the details.
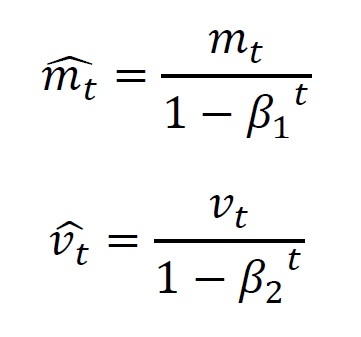
The update formula is as follows.
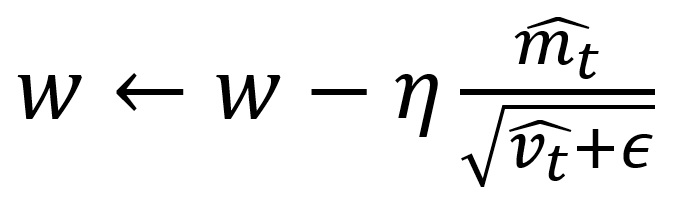
where is a very small value to avoid zero division on a computer.
The recommended values for is 0.9, and for 0.999.
Deep Learning asks you to create a network which consists of multiple logical calculation elements, such as convolution or full connection. If the AI you want to create is more complicated, the element count will be larger. As a result, the parameter count will be bigger. And then, the learning process will be more difficult. Adam, which we introduced here, is a method to vary the learning constant per parameter. Therefore, it is effective especially when the parameter count is huge. This is one reason why recent studies often took advantage of this.