Lesson 15 Convolution
Convolution is one of conventional image recognition methods. That is often used to reduce the number of input values for neural network. When the number of given input values is large, the number of parameters becomes large accordingly. As a result, the repetition number for sufficiently small error also becomes large as well. Utilizing image processing technology together with machine learning is valid to make the neural network size smaller.
Image file consists of colored points. Each point is called pixel, and the number depends on the resolution.
When you magnify an actual image, you can see each pixel with your eyes.

The color difference of two adjacent pixels doesn't have any special meaning for image recognition in many cases. Collecting some pixels around a location and getting another value from the pixel values is often enough for that. Convolution is valid for this purpose.
When PCs render colors, the system often has values for three primary colors (RGB), which are red, blue, and yellow, with the 256 gradation from 0 to 255. As a result, the system is supposed to render about 1.6 million colors.
Now, we assume an image with three pixels in width and height. An example of the RGB values is shown below.
Image processing recognizes each RGB as an individual image, and call them channels.
When we think of dimensions for those values, we can recognize them as three dimensions data, as there are two dimensions for width and height, and also one more dimension for 3 channels of RGB.
Each pixel value is from 0 to 255. We are going to discuss how the system calculates something for a new image.
To make our discussion simply, we assume a grey scale image. The channel number is one, and we will define a filter for this calculation process. An example is shown below.
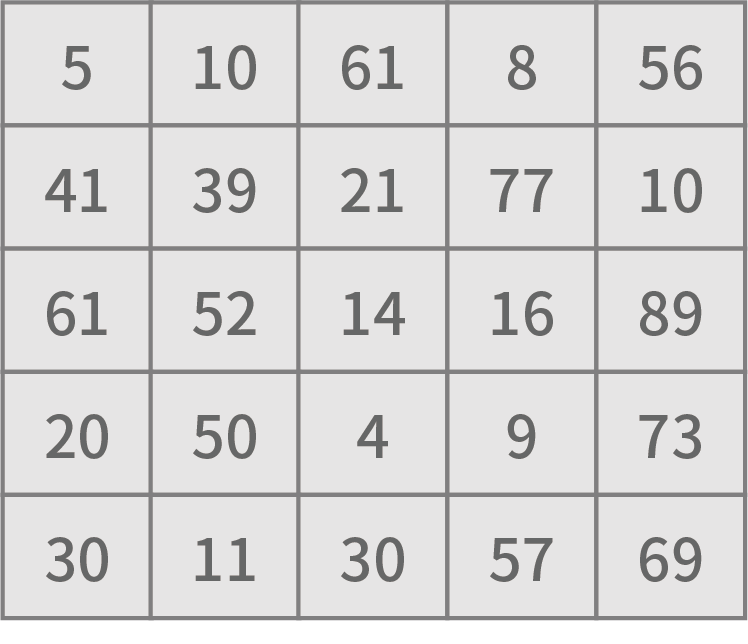

This filter has -1 at the top middle, 1 at the center, and 0 at the others. The system puts the filter on the original image from the top left to the bottom right, multiply a value from the image with the corresponding piled value, and sum up everything. Finally, we will get a new value. A new image will be created by copying each new value to the corresponding pixel value. The actual result would be like this.
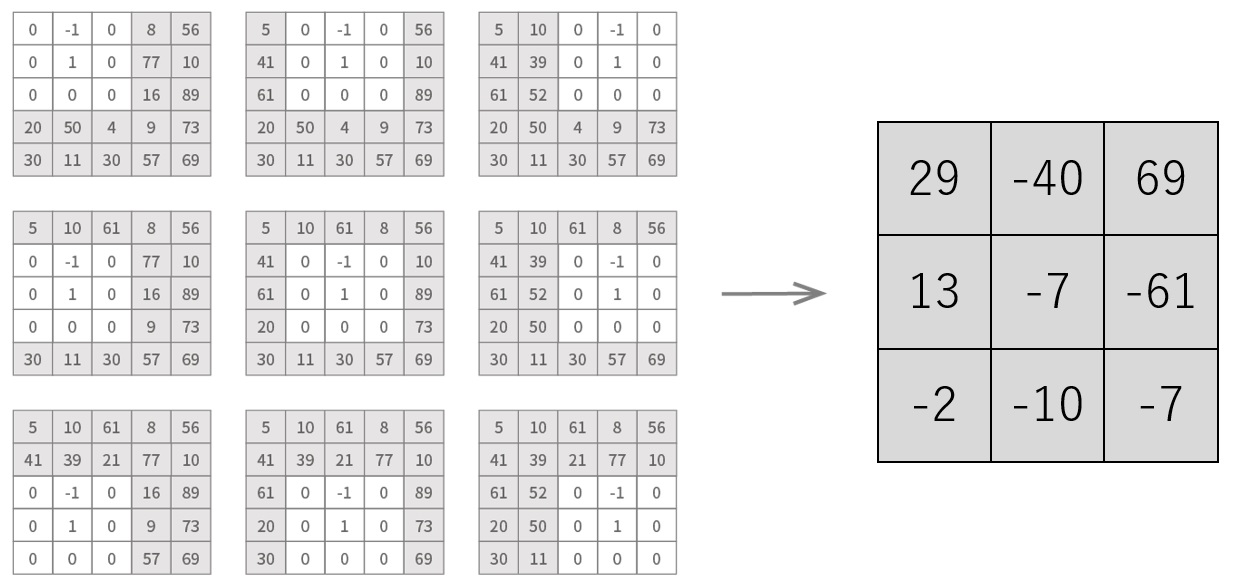
Where, we prepare a filter with three pixels in width and height, and the sliding distances for the convolution process are one pixel in width and height. Finally, we get an image with three pixels in width and height.
Now, we are going to see the calculation process on multi-channel image.
As we already discussed, convolution process with one filter on a gray scale image will output an one channel image. Regarding multi-channel image, the filter count is the input channel count, and convolution process will create the same count of images with the same size. Then, the pixel values at the same location of each output image will be summed up. As a result, you will get one image. If you prepare multiple filter groups, you can get multi-channel output image. It means the channel count of input and output may differ.
Now let's see a calculation example.
Suppose we have a three-channel image and two filter groups as follows.
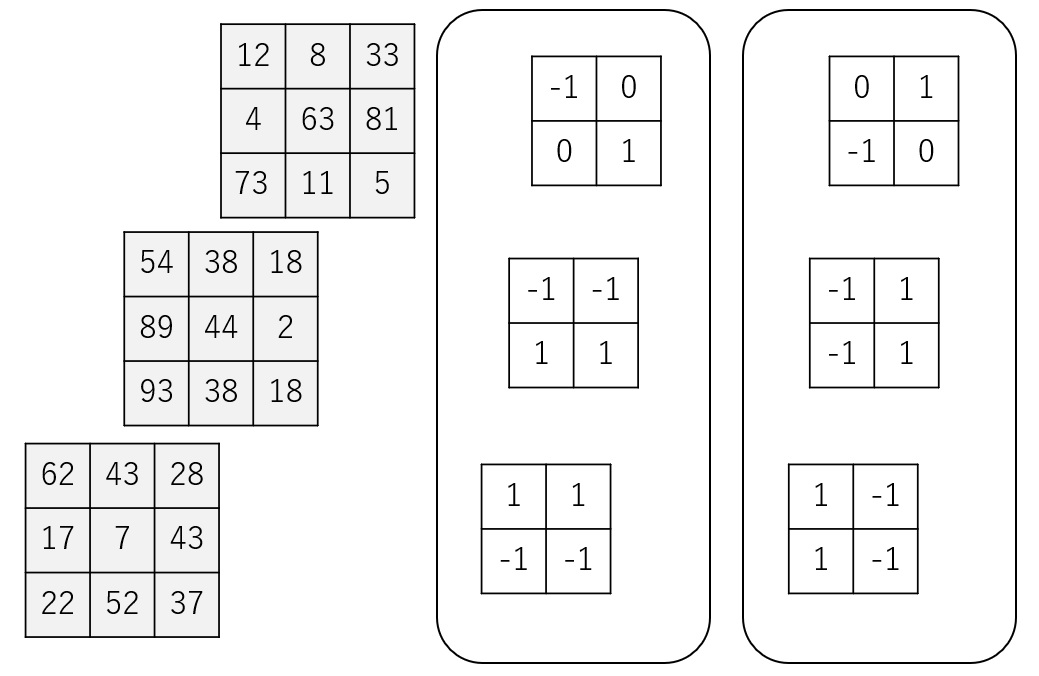
We will execute convolution with the first filter group.
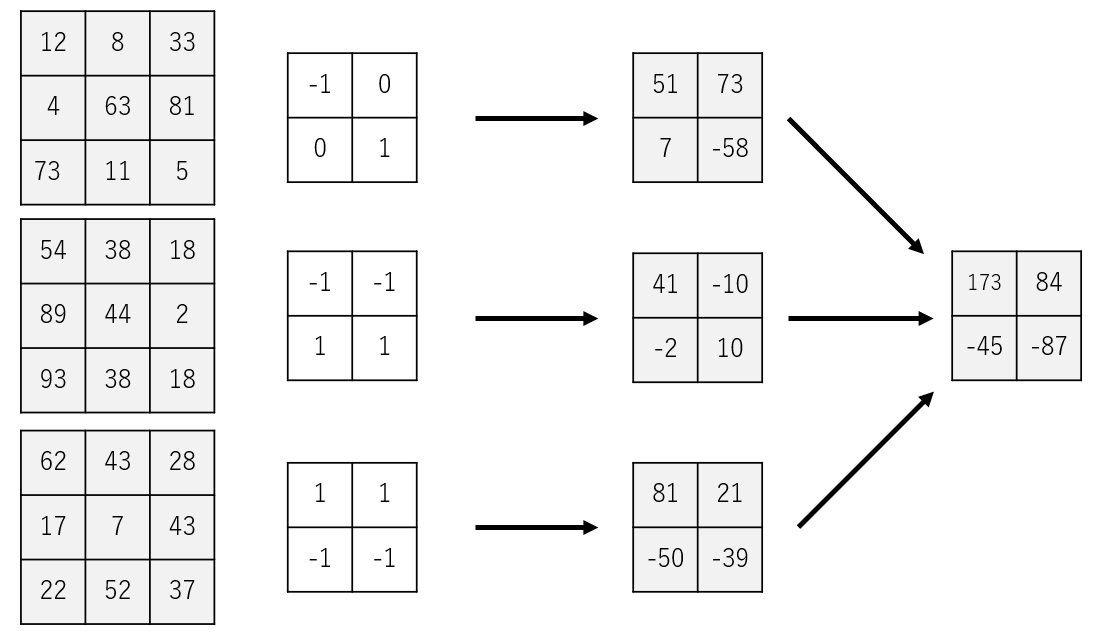
And then, we will use the second filter group.
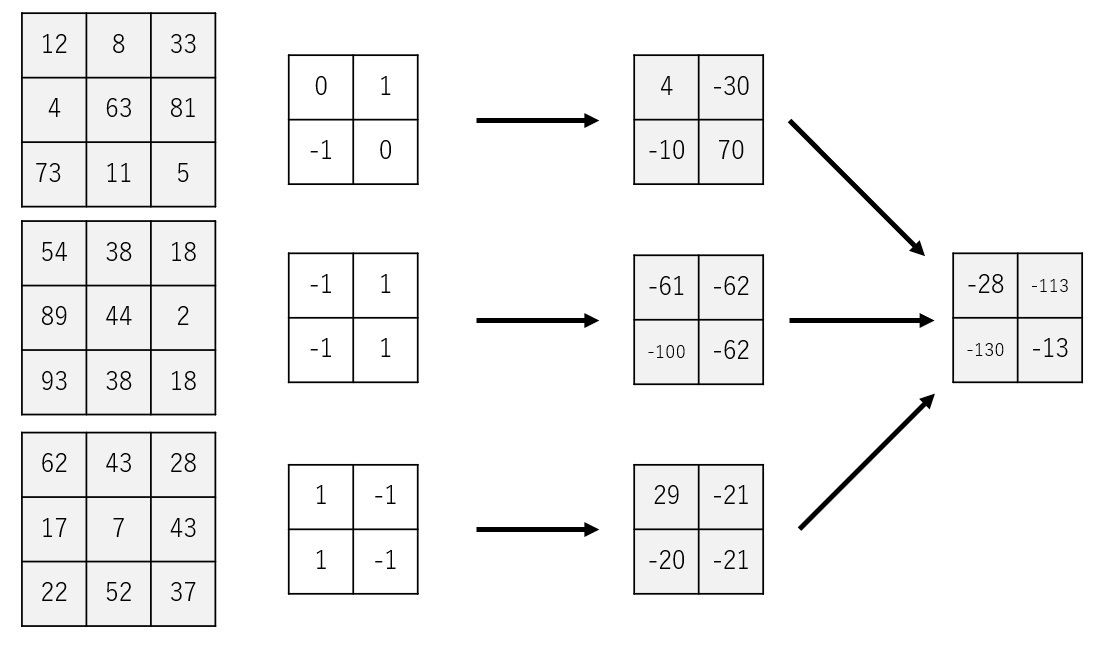
In the example above, we can get a two-channel 2x2 image from a three-channel 3x3 image.
As we explained here, convolution process creates a new image with smaller pixel size, keeping the characteristics of an original image. When we use this as an input for a neural network, we can reduce the number of parameters for learning, and as a result, the total time for learning process will be less.